
70-475 Exam Questions - Online Test
70-475 Premium VCE File

150 Lectures, 20 Hours

Our pass rate is high to 98.9% and the similarity percentage between our exam 70 475 and real exam is 90% based on our seven-year educating experience. Do you want achievements in the Microsoft 70-475 exam in just one try? I am currently studying for the microsoft 70 475. Latest 70 475 exam, Try Microsoft 70-475 Brain Dumps First.
Check 70-475 free dumps before getting the full version:
NEW QUESTION 1
You are designing a solution for an Internet of Things (IoT) project.
You need to recommend a data storage solution for the project. The solution must meet the following
requirements: Allow data to be queried in real-time as it streams into the solution Provide the lowest amount of latency for loading data into the solution. What should you include in the recommendation?
Allow data to be queried in real-time as it streams into the solution Provide the lowest amount of latency for loading data into the solution. What should you include in the recommendation?
- A. a Microsoft Azure SQL database that has In-Memory OLTP enabled
- B. a Microsoft Azure HDInsight Hadoop cluster
- C. a Microsoft Azure HDInsight R Server cluster
- D. a Microsoft Azure Table Storage solution
Answer: A
Explanation: References:
https://azure.microsoft.com/en-gb/blog/in-memory-oltp-in-azure-sql-database/
NEW QUESTION 2
You need to implement rls_table1.
Which code should you execute? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: Box 1: Security Security Policy
Example: After we have created Predicate function, we have to bind it to the table, using Security Policy. We will be using CREATE SECURITY POLICY command to set the security policy in place.
CREATE SECURITY POLICY DepartmentSecurityPolicy
ADD FILTER PREDICATE dbo.DepartmentPredicateFunction(UserDepartment) ON dbo.Department WITH(STATE = ON)
Box 2: Filter
[ FILTER | BLOCK ]
The type of security predicate for the function being bound to the target table. FILTER predicates silently filter the rows that are available to read operations. BLOCK predicates explicitly block write operations that violate the predicate function.
Box 3: Block
Box 4: Block
Box 5: Filter
NEW QUESTION 3
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while the others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Microsoft Azure deployment that contains the following services: Azure Data Lake Azure Cosmos DB Azure Data Factory Azure SQL Database
You load several types of data to Azure Data Lake.
You need to load data from Azure SQL Database to Azure Data Lake. Solution: You use the AzCopy utility.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
Explanation: Note: You can use the Copy Activity in Azure Data Factory to copy data to and from Azure Data Lake Storage Gen1 (previously known as Azure Data Lake Store). Azure SQL database is supported as source.
References: https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-data-lake-store
NEW QUESTION 4
Which service solution and which table storage solution should you recommend for DB2? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.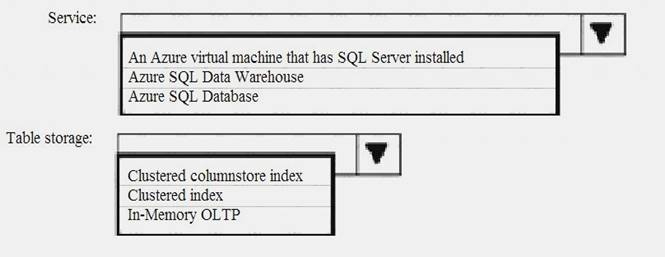
Answer:
Explanation: Box 1: Azure SQL Data Warehourse
Scenario: Relecloud plans to implement a data warehouse named DB2. Box 2: Clustered Columnstore index
Columnstore index is a new type of index introduced in SQL Server 2012. It is a column-based non-clustered index geared toward increasing query performance for workloads that involve large amounts of data, typically found in data warehouse fact tables.
A clustered columnstore index is the physical storage for the entire table. Scenario:
Relecloud identifies the following requirements for DB2: DB2 must be able to store more than 40 TB of data.
References: https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-overview
NEW QUESTION 5
Your company builds hardware devices that contain sensors. You need to recommend a solution to process the sensor data and. What should you include in the recommendation?
- A. Microsoft Azure Event Hubs
- B. API apps in Microsoft Azure App Service
- C. Microsoft Azure Notification Hubs
- D. Microsoft Azure IoT Hub
Answer: A
NEW QUESTION 6
You have an Apache Hadoop system that contains 5 TB of data.
You need to create queries to analyze the data in the system. The solution must ensure that the queries execute as quickly as possible.
Which language should you use to create the queries?
- A. Apache Pig
- B. Java
- C. Apache Hive
- D. MapReduce
Answer: D
NEW QUESTION 7
You plan to deploy a Microsoft Azure Data Factory pipeline to run an end-to-end data processing workflow. You need to recommend winch Azure Data Factory features must be used to meet the Following requirements: Track the run status of the historical activity.
Enable alerts and notifications on events and metrics.
Monitor the creation, updating, and deletion of Azure resources.
Which features should you recommend? To answer, drag the appropriate features to the correct requirements. Each feature may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: Box 1: Azure Hdinsight logs Logs contain historical activities. Box 2: Azure Data Factory alerts Box 3: Azure Data Factory events
NEW QUESTION 8
You have the following script.
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the script.
NOTE: Each correct selection is worth one point.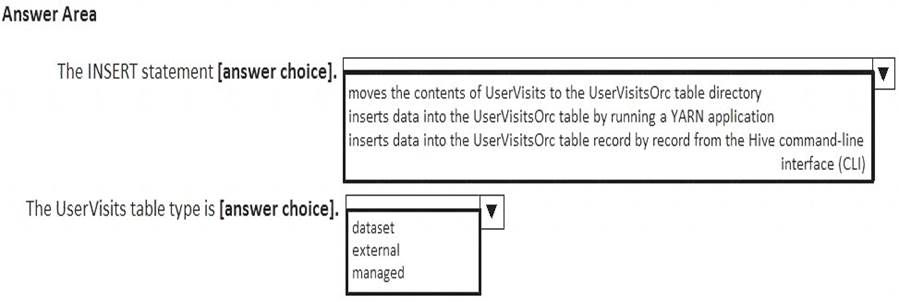
Answer:
Explanation: A table created without the EXTERNAL clause is called a managed table because Hive manages its data.
NEW QUESTION 9
Users report that when they access data that is more than one year old from a dashboard, the response time is slow.
You need to resolve the issue that causes the slow response when visualizing older data. What should you do?
- A. Process the event hub data first, and then process the older data on demand.
- B. Process the older data on demand first, and then process the event hub data.
- C. Aggregate the older data by time, and then save the aggregated data to reference data streams.
- D. Store all of the data from the event hub in a single partition.
Answer: C
NEW QUESTION 10
You plan to implement a Microsoft Azure Data Factory pipeline. The pipeline will have custom business logic that requires a custom processing step.
You need to implement the custom processing step by using C#.
Which interface and method should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.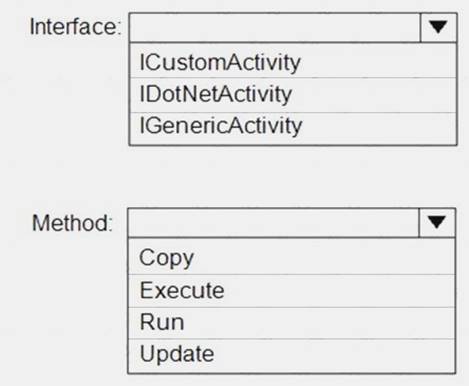
Answer:
Explanation: References:
https://github.com/MicrosoftDocs/azure-docs/blob/master/articles/data-factory/v1/data-factory-use-custom-activ
NEW QUESTION 11
You are using a Microsoft Azure Data Factory pipeline to copy data to an Azure SQL database. You need to prevent the insertion of duplicate data for a given dataset slice.
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Set the External property to true.
- B. Add a column named SliceIdentifierColumnName to the output dataset.
- C. Set the SqlWriterCleanupScript property to true.
- D. Remove the duplicates in post-processing.
- E. Manually delete the duplicate data before running the pipeline activity.
Answer: BC
NEW QUESTION 12
You need to recommend a data analysis solution for 20,000 Internet of Things (IoT) devices. The solution must meet the following requirements:
• Each device must be identified by using its own credentials.
• Each device must be able to route data to multiple endpoints.
• The solution must require the minimum amount of customized code. What should you recommend?
- A. Microsoft Azure Notification Hubs
- B. Microsoft Azure IoT Hub
- C. Microsoft Azure Service Bus
- D. Microsoft Azure Event Hubs
Answer: D
NEW QUESTION 13
You have a Microsoft Azure Data Factory pipeline.
You discover that the pipeline fails to execute because data is missing. You need to rerun the failure in the pipeline.
Which cmdlet should you use?
- A. Set-AzureAutomationJob
- B. Resume-AzureDataFactoryPipeline
- C. Resume-AzureAutomationJob
- D. Set-AzureDataFactotySliceStatus
Answer: B
NEW QUESTION 14
You have data generated by sensors. The data is sent to Microsoft Azure Event Hubs.
You need to have an aggregated view of the data in near real-time by using five minute tumbling windows to identity short-term trends. You must also have hourly and a daily aggregated views of the data.
Which technology should you use for each task? To answer, drag the appropriate technologies to the correct tasks. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: Box 1: Azure HDInsight MapReduce
Azure Event Hubs allows you to process massive amounts of data from websites, apps, and devices. The Event Hubs spout makes it easy to use Apache Storm on HDInsight to analyze this data in real time.
Box 2: Azure Event Hub
Box 3: Azure Stream Analytics
Stream Analytics is a new service that enables near real time complex event processing over streaming data. Combining Stream Analytics with Azure Event Hubs enables near real time processing of millions of events per second. This enables you to do things such as augment stream data with reference data and output to storage (or even output to another Azure Event Hub for additional processing).
NEW QUESTION 15
You have a Microsoft Azure Data Factory pipeline.
You discover that the pipeline fails to execute because data is missing. You need to rerun the failure in the pipeline.
Which cmdlet should you use?
- A. Set-AzureRmAutomationJob
- B. Set-AzureRmDataFactorySliceStatus
- C. Resume-AzureRmDataFactoryPipeline
- D. Resume-AzureRmAutomationJob
Answer: B
Explanation: Use some PowerShell to inspect the ADF activity for the missing file error. Then simply set the dataset slice to either skipped or ready using the cmdlet to override the status.
For example:
Set-AzureRmDataFactorySliceStatus `
-ResourceGroupName $ResourceGroup `
-DataFactoryName $ADFName.DataFactoryName `
-DatasetName $Dataset.OutputDatasets `
-StartDateTime $Dataset.WindowStart `
-EndDateTime $Dataset.WindowEnd `
-Status "Ready" `
-UpdateType "Individual" References:
https://stackoverflow.com/questions/42723269/azure-data-factory-pipelines-are-failing-when-no-files-available-
NEW QUESTION 16
Your company has a Microsoft Azure environment that contains an Azure HDInsight Hadoop cluster and an Azure SQL data warehouse. The Hadoop cluster contains text files that are formatted by using UTF-8 character encoding.
You need to implement a solution to ingest the data to the SQL data warehouse from the Hadoop cluster. The solution must provide optimal read performance for the data after ingestion.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation: SQL Data Warehouse supports loading data from HDInsight via PolyBase. The process is the same as loading data from Azure Blob Storage - using PolyBase to connect to HDInsight to load data.
Use PolyBase and T-SQL Summary of loading process: Recommendations
Create statistics on newly loaded data. Azure SQL Data Warehouse does not yet support auto create or auto update statistics. In order to get the best performance from your queries, it's important to create statistics on all columns of all tables after the first load or any substantial changes occur in the data.
NEW QUESTION 17
Which technology should you recommend to meet the technical requirement for analyzing the social media data?
- A. Azure Stream Analytics
- B. Azure Data Lake Analytics
- C. Azure Machine Learning
- D. Azure HDInsight Storm clusters
Answer: A
Explanation: Azure Stream Analytics is a fully managed event-processing engine that lets you set up real-time analytic computations on streaming data.
Scalability
Stream Analytics can handle up to 1 GB of incoming data per second. Integration with Azure Event Hubs and Azure IoT Hub allows jobs to ingest millions of events per second coming from connected devices, clickstreams, and log files, to name a few. Using the partition feature of event hubs, you can partition computations into logical steps, each with the ability to be further partitioned to increase scalability.
Recommend!! Get the Full 70-475 dumps in VCE and PDF From 2passeasy, Welcome to Download: https://www.2passeasy.com/dumps/70-475/ (New 102 Q&As Version)
- All About Exact 70-467 practice test
- The Renovate Guide To 70-461 practice test
- Microsoft 70-743 Exam Dumps 2021
- Breathing Microsoft 70-535 exam dumps
- The Down to date Guide To 70-347 exam dumps
- The Secret of Microsoft 70-413 practice test
- The Most up-to-date Guide To 70-534 exam dumps
- Improved 70-413 Exam Study Guides With New Update Exam Questions
- Free 70-765 Study Guides 2021
- Replace Microsoft 70-413 exam question